Para mis seguidores en español, la Comunidad CRM/365 tendra un evento muy oportuno para aprender sobre las novedades de Dynamics 365
No te pierdas la Mesa de Expertos este próximo miércoles 16 de Noviembre para aprender sobre las novedades del nuevo lanzamiento que estará disponible en Diciembre 2016 para CRM Online.
Si tienes preguntas esta es tu oportunidad para que respondamos a tus preguntas. Simplemente envia tu pregunta por anticipado medio de Twitter con el hashtag #enfoco365.
Para registrarte en el evento sigue este link: http://www.comunidadcrm.com/blog/event/16-noviembre-microsoft-dynamics-365-comienzo-una-nueva-mesa-expertos/#.WCdO8PkrKUk
Dependiendo del tiempo, haremos demostraciones de los nuevos features tal como la nueva navegación, el nuevo diseñador de procesos, los nuevos editable grids y el nuevo modelo de aplicaciones introducido por Dynamics 365. Esperamos verlos pronto!
Saturday, November 12, 2016
Thursday, October 13, 2016
How to modify the Quick Create form for tasks and activities
This is one of those post that will explain a problem we
have in CRM but unfortunately there is no great solution I know so far for this
problem.
When you insert the social pane in a given entity, you will
notice that there is a quick way to add activities (phone call, task, etc.)
were the user does not have to leave the screen in order to add these records:

This makes the user experience great for adding tasks to a
given record quickly. However, while this is beautiful for customer demos, in
real life things are rarely this simple. For example, we’ve had to add another
required field on the task called “Task Type”, but how can I add this field on
this form?!
Things that I have tried:
1.
Modify the quick create view on Task entity.
However, there are no “Quick Create” forms on task entity:

2.
Try to see if the Quick Create forms are defined
at the parent entity “Activity”. However, this entity has no forms defined
since it is a special entity:

3.
Then I thought maybe I can create my own quick
create form in the task entity and set the form priority higher so it supersedes
the one that comes out of the box. However, when I check the Quick Create form
order I can only see my form:


It seems like
the out-of-the-box quick create form is completely hidden. When I publish my
changes and look my new form is not really used
4.
Then I thought maybe we can remove “Add Task”
from the social pane so that users would be forced to add tasks the old way and
be able to use the form we need. However, the Social Pane is not very
configurable and the only things that can be set is whether to show Activities
or Notes by default, which is really not useful.
So this actually forced us in some cases to remove the
social pane all together and go back to the sub-grid approach. However, if you
need to capture notes then you might be out of luck!
Also note that in the Quick Create menu in CRM, when you try
“Task” it will actually open the default full form, rather than any Quick
Create form that you define, so you have control but you cannot leverage the
quick create feature for activities apparently.

We also tried to hide the activities from appearing in the
quick create menu but this was not possible because you cannot unselect the
setting to show activities in the quick create menu. This is perhaps one of the
most annoying things with quick create and stems from the fact that Microsoft
has locked down the configurability of this feature which often just renders it
useless in the real world but only pretty for customer demos. This sadly seems
to be the case for many features that are also locked down for extension or
configurability. If you have any workaround I’d be very happy to hear!
Thursday, October 6, 2016
Transporting SLAs in a CRM solution
This post explores some of the nuisances when transporting
SLAs in a CRM solution. I did most of my tests in CRM 2015 and CRM 2016
environments but behavior might vary between different versions.
When you include an SLA to the solution there are some
special things that will happen. In this example, I have a blank solution and I
have added only my SLA to the solution. As expected, the only component in the
solution is the SLA itself:

However, after you export the solution for the first time,
you will notice that magically some processes get added to your solution
automatically after export without any indication that this has happened:
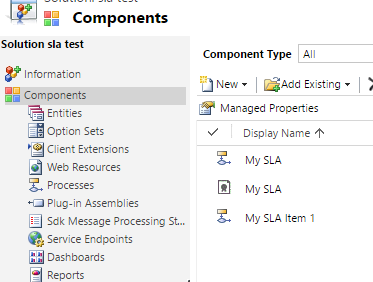
Furthermore, in older versions of CRM (2015) you will also
see that the “Process”, “Case” and “SLA KPI Instance” entities get added to the
solution magically which can be quite confusing:

But why is this happening? The reason why you see some processes
added to the solution is because SLAs are implemented as CRM processes
(workflows) behind the scenes, so at the moment you export an SLA, you need to
export at the same time the process definitions for the SLA. There wil be one
process per SLA plus one additional process for each SLA Item you have added to
your SLA (1 item in my example). That is because SLA Items are also implemented
as workflows. Now, the question of why we have to surface these implementation
details to the user is in my opinion a bug, there is no reason to show the user
these components in the solution and should be hidden because they are
implementation details of the SLA that happen behind the scenes and causes
confusion more than anything about what these processes are. If you try to open
one of these processes you will notice that they are read only and completely
system managed depending on the SLA and SLA Item definitions that you have
provided in the user interface.
Another problem with such implementation is that if you
rename the SLA Items, then their corresponding workflow/process is not renamed
accordingly which can cause even more confusion since they will keep the
original name that was given to the SLA Item during creation. I have even run
in a situation in which solution export fails because it could not find the
corresponding SLA Item process once I had renamed the SLA Item (although I was
not able to reproduce this problem consistently).
The reason why you see the “Case”, “Process” and “SLA KPI
Instance” entities added to the solution in CRM 2015 is most likely a bug and
something that was fixed in CRM 2016. Even if you remove these entities from
the solution, they will get added back automatically next time you export the
solution so not worth trying to remove them manually!
Another thing I wanted to explore is how the Business Hours
get transported in the solution. For example, I have defined my business hours
as follows:

I have found out be inspecting the solution XML that the
business hours are not included at all in the solution, therefore when you
transport the SLA to another environment the business hours will be blank for
the given SLA. You will then need to set it manually in the target environment.
I have researched whether I could use the Configuration Migration utility that
comes with the SDK in order to migrate business hours and include in the
solution deployment package but as it turns out both the Business Hours and the
Holiday Schedule are implemented as entries in the “Calendar” entity which is
not supported by the Configuration Migration tool, and AFAIK is also not
possible to import these using Excel import file. Therefore, you have no option
than to re-create these records in your target environment (manually or
automate via SDK) and link them to the existing SLA. You might be able to
import the individual “Holiday” records to the Holiday Schedule in an automated
fashion such as import but I have not validated that far what can be done.
Luckily creating the Business Hours and Holiday Schedule is
not a very long task, and you should be able to create them only once in each
target environment. After than re-importing an existing SLA should preserve the
link to the Business Hours you had set previously.
Friday, September 30, 2016
Tuesday, September 27, 2016
State Machines in CRM for Status Transitions
Those who come more from an engineering background might be
familiar with the concept of state machines. This article explains an easy
implementation in CRM.
State machines are basically a way to model an object’s life
cycle, including the different states or statuses it can have along with the
transitions that are possible to go from one state to another. In an example
below we have an airline ticket and how the status of the ticket can transition
in different scenarios:

The key about state machines is that it restricts invalid
state changes. For example, you cannot go from “Used” to “paid” because once
the ticket is used, it can no longer change. In some sate machines you might
also want to specify which states are read-only as opposed to “editable” and
you can even define additional conditions such as having the correct privilege
(e.g. only a manager is able to issue a refund).
Now you can apply this concept of state machines to CRM
entities. Although these state machines can be quite complex in real life, in
CRM entities most of the times this is not too complex. If you have a simple
state machine to model, there is the feature in CRM (often overlooked) called
status transitions.

You can actually define which status can lead to which
status. Below is the CRM implementation of the state machine of my example:

Note that CRM requires that for each “Active” status you
must have defined a valid transition to an “inactive” state (at least this is
mentioned in the documentation here: https://technet.microsoft.com/en-us/library/dn660979.aspx
although I’m not sure where it is enforced if it is).
Now in the CRM form you will notice that it will remove the
invalid state transitions from the available status reasons. For example, if my
record is on status reason “Reserved” I cannot change it to “Ticketed” because
I need to mark it as paid first:

If I had not defined a transition from the current status
reason to an “Inactive” state then I am not able to de-activate the record and
change the state to “Inactive”:

Also note that the transition validations are valid even
outside the scope of CRM forms. If you try to perform an invalid status update
from workflow/plugin/SDK you would get this error:
Monday, September 26, 2016
CRM SLA Failure and Warning times, not what you would expect!
When you configure an SLA item in CRM, you have the option
to specify the “Failure” and “Warning” times as a duration.

The format of these fields Is the same as any other CRM
duration field, but what does it really mean? For example, if you set it to 10
days, is it 10 calendar days? Is it 10 business days? You might be surprised it
is neither!
First let’s backtrack a little bit and look at the SLA definition.
At the SLA level you can define “Business Hours” which captures the business
days of the week, business hours of the day as well as any holidays during
which an SLA should not apply. Let’s see what happens to your 10 day SLA
depending on your business hour configuration in different scenarios. For
simplicity I will assume you do not have “pause” when the record is on-hold.
1.
No Business Hours
If you leave this “Business Hours” field blank, then the
system will assume 24x7 and therefore, the “Failure” and “Warning” times you
set are simply calendar days, it will be simply a duration which is quite straight-forward.
Therefore, when you create the record, you will have exactly 10 days (240
hours) before the SLA fails.
2.
Business Hours Configured (Work Days only)
In this case you configure your Business Hours only for the
work days (e.g. Mon-Fri) but you leave the work hours as 24-hour (i.e. your
business day has 24 hours):

In this case, what happens to your 10-day SLA is that it
becomes a 10 business day SLA. Therefore, when you create a case, you will have
14 calendar days before the SLA fails because the weekend days will not be
counted.
3.
Business Hours Configured (Including Work Hours)
Now this is where things get really messy unexpectedly.
Imagine you configure your business hours to be Mon-Fri from 09:00 to 17:00 so
that you have 8 working hours per business day. What happens to the 10-day SLA
failure?

I create a case and to my surprise, the system gives me
almost 42 calendar days to resolve the case before failing SLA:

This seems really random. What happens here is that the “Failure”
time of 10 days is actually a duration
(not the actual count of calendar or business days). In other words, the SLA
will fail after 240 “business hours”. Because I only have 8 business hours per
day then this means 30 business days and because of the weekends it ends up
giving me almost 42 days. This is definitely not what I would expected when I
configured by failure time to 10 days. Therefore, I just decided to leave my
work hours as 12am-12am (24 hours) and then I would fall under #2 above in
which I get 10 business days for resolving the case as I expected.
Adding holidays to your calendar works similar to the work
days, it will just exclude the entire day from the count. Do not expect the
timer to “pause” when you are outside of working hours because the timer has
actually been increased to account for the time that you will have outside of
business hours, so the timer countdown is always real time (duration) and can
only pause when you configure pause for “on-hold” status.
I hope you find this useful, I think unless you have really
fast SLAs (defined in hours or minutes) it almost makes no sense to think about
configuring working hours. My conclusion is that if you SLAs which are defined
in number of days you most likely should leave the work hours to 24 hours in
order for the timer to make sense. Alternatively if you keep working hours you would need to define your SLA items as a function of business hours, so for my example, if the business hours are from 9am to 5pm then that means that for a 10 business day SLA I would need to define my failure time as 10*(number of business hours per day) = 80 hours. The small caveat here is that if you change your business hours then you need to update all your SLA items as the above formula could have changed. In either case you should still configure your workdays to
exclude weekends if desired though.
Tuesday, September 20, 2016
CRM Alternate keys with OptionSet fields
The alternative keys feature introduced in CRM 2015 U1 turns
out to be extremely useful, especially for integration scenrios in which you
might want to keep a record of an “external key” from another system or you
want to enforce duplicate prevention (for real).
In some cases you would like to make the alternative key
contain an OptionSet type of field. For example, I wanted to define an
alternative key based on “Contact Type” and “Email” so that CRM could check
that no contacts of the same type with the same email address.
However, when you try to define the key on the contact
entity I could no select my “Contact Type” field as part of the key:

So I can see a number of fields and realize that only fields
of numeric or text value are available to pick. After some research I found
that it is documented in the SDK that only
these fields can be added to a key:


Now I am able to add the calculated field to my key:

After this is done, I can test to make sure I can create
both a nurse and a doctor with the same email but if I try to create 2 nurses
with the same email I get the error:

So this works. It is not the most elegant solution since you
are essentially duplicating data. However, if you must include an OptionSet
field as part of a key this could be an easy way to enforce it :-)
Enjoy!!
Subscribe to:
Posts (Atom)